Background
At Eventbrite, we identified in our 3-year technical vision that one of our goals is to enable autonomous dev teams to own their code and architecture so as to be able to deliver reliable, high quality and cost effective solutions to our customers. However, this autonomy does not mean that our team has to work in complete isolation from other teams in order to achieve their goals.
Over the past year, we have started our transition from our monolithic Django + Python approach to a microservices architecture; we selected gRPC as our low-latency protocol for inter-microservice communication. One of the main challenges that we face is sharing Protobuf files between teams for generating client libraries. We want it to be as easy as possible by avoiding unnecessary ceremonies and integrating into team development cycles.
Challenges managing Protobuf definitions
Since our teams have full autonomy of their code and infrastructure, they will have to share Protobuf files. Multiple sharing strategies are available, so we identified key questions:
Should we copy and paste .proto files in every repository where they are needed? This is not a good idea and could be frustrating for the consuming teams. We should avoid any error-prone or manual activity in favor of a fully automated process. This will drive consistency and reduce toil.
How will changes in .proto files impact clients? We should implement a versioning strategy to support changes.
How do we communicate changes to clients? We need a common place to share multiple versions with other teams and adopt a standard header to client expectations, such as Deprecation and Sunset.
Our proposed solution
We will maintain protobuf files within the owning service’s repository to simplify ownership. The code owners are responsible for generating the needed packages for their clients. Their CI/CD pipeline will automatically generate the library code from the protobuf file for each target language.
Packages will be published in a central place to be consumed by all client teams. Each package will be versioned for consistency and communication. Before deprecating and sunsetting any package version, all clients must be notified and given enough time to upgrade.
Repository Structure
In our opinion, having a monorepo for all protobuf definitions would slow down the teams’ development cycles: each modification to a Protobuf definition would require a PR to publish the change in the monorepo, waiting for an approval before generating required artifacts and distributing them to clients. Once the package was published, teams would have to update the package and publish a new version of their services. We need to keep the Protobuf files with their owning service.
Project Structure
The project’s organization should provide a clear distinction between the services that exist in the project and the underlying Protobuf version that the package is implementing. The proto folder will hold the definition of each proto file with a correctly formed version using the package specifier. The service folder will hold the implementation of each gRPC service which is registered against the server.

This approach will allow us to publish a v2 version of our service with breaking change, while we continue supporting the v1 version. We should take into consideration the next points when we publish a new version of our service:
- Try to avoid breaking changes (Backward and forward compatibility)
- Do not change the version unless making breaking changes.
- Do change the version when making breaking changes.
Proto file validation
To make sure the proto files do not contain errors and to enforce good API design choices we recommend using Buf as a linter and a breaking change detector. It should be used on a daily basis as part of the development workflow, for example, by adding a pre-commit check to ensure our proto files do not contain any errors.
Following our “reduce toil over automation” principle, we added a task in our CI/CD pipelines in CircleCI. A Docker image is available to add some steps for linting and breaking change detection. It helps us to ensure that we publish error-free packages:
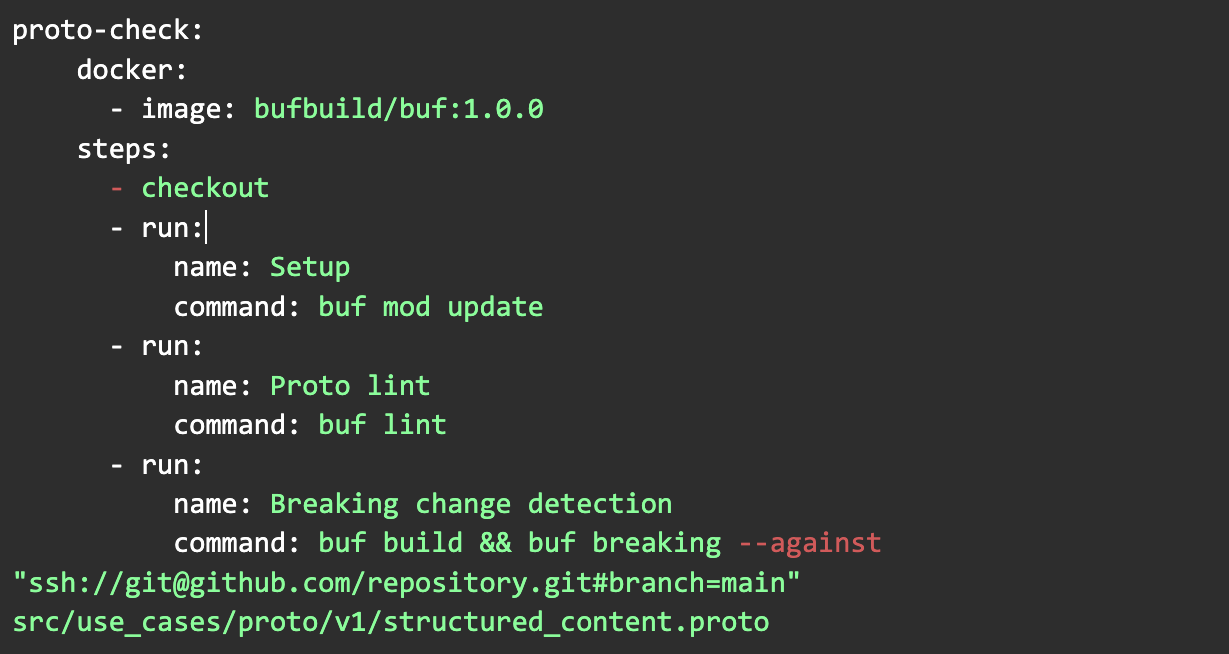
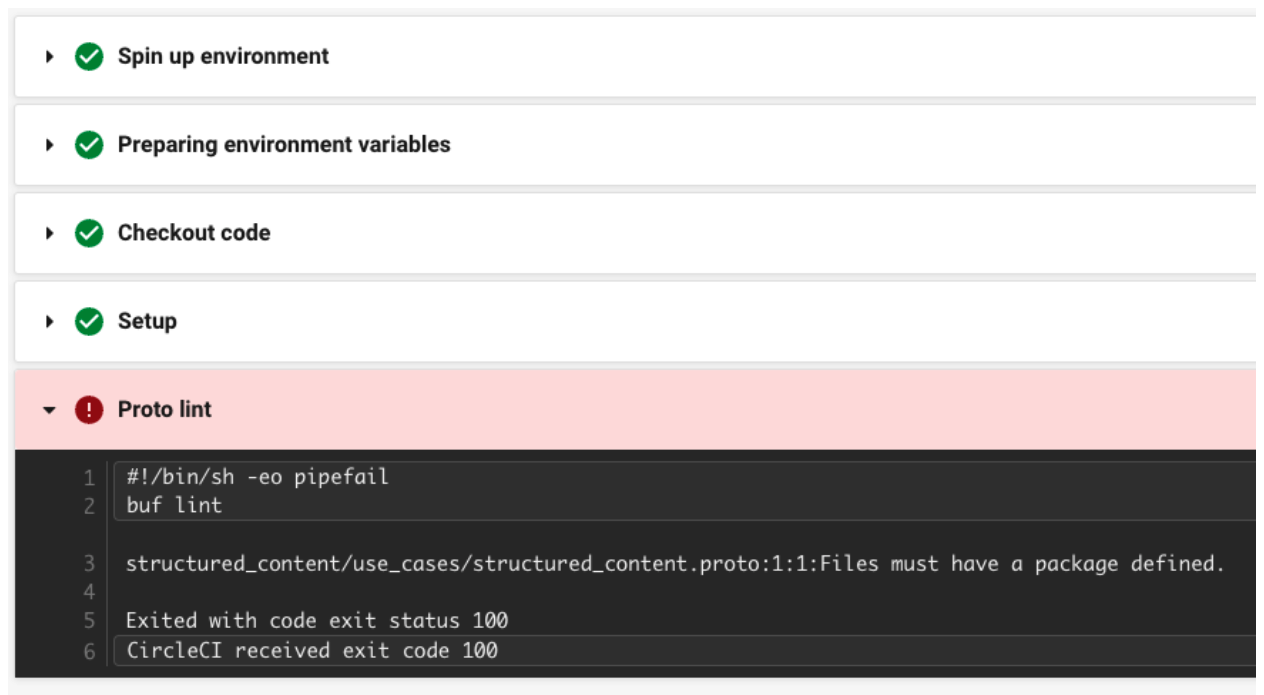
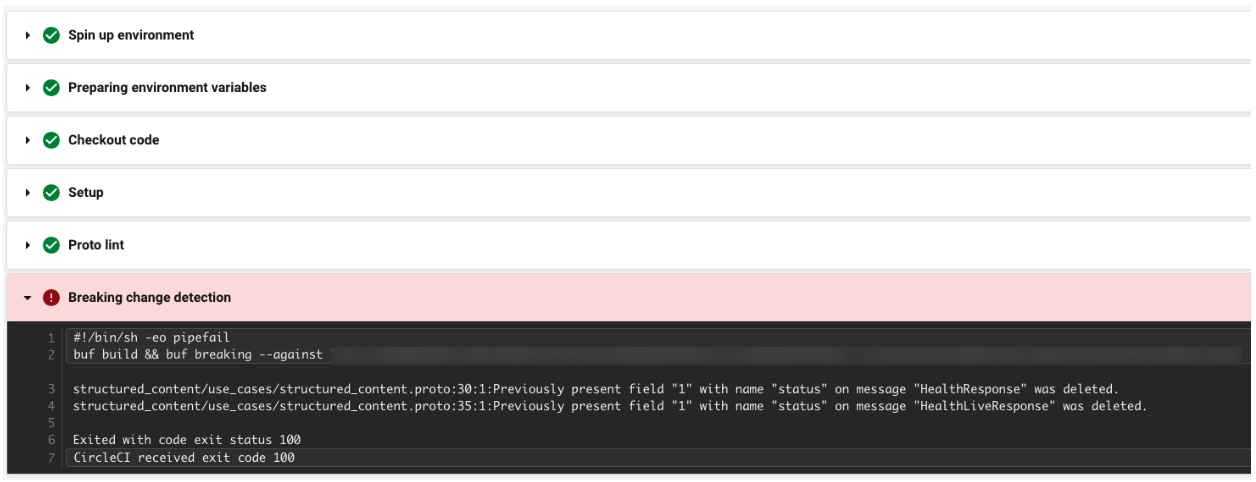
If a developer pushes breaking changes or changes with linter problems, our CI/CD pipelines in CircleCI will fail as can be seen in the pictures below:
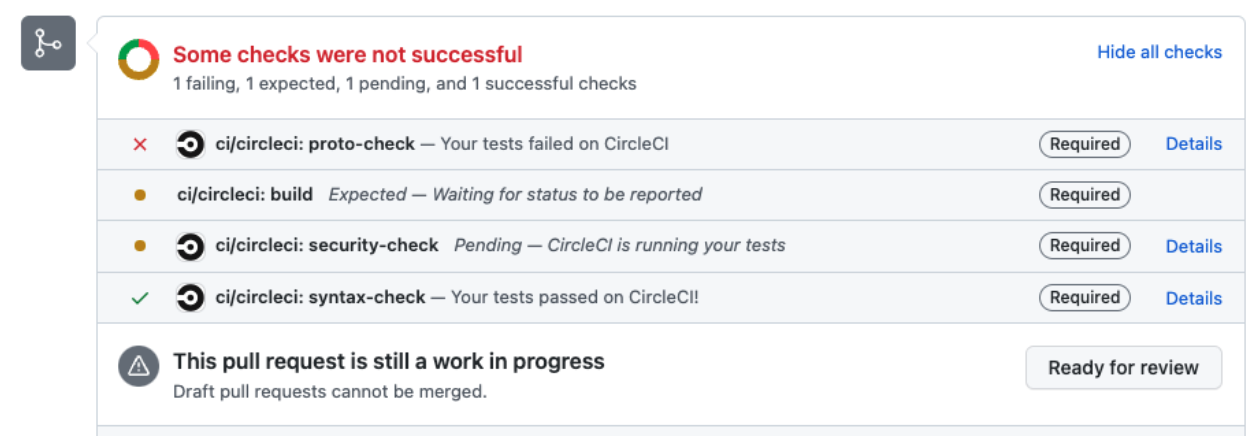
Linter problems
Breaking changes
Versioning packages
Another challenge is building and versioning artifacts from the protobuf file-generated code. We selected Semantic Versioning as a way to publish and release packages’ versions.
The package name should reflect the service name and follow the conventions established by the language, platform, framework and community.
Generating code for libraries
We have set up an automated process in CircleCI to generate code for libraries. Once a proto file is changed and tagged, CircleCI detects the changes and begins generating the code from the proto file.
We compile it using protoc. To avoid the burden of installing it, we use a Docker image that contains it. This facilitates our local development as well as CI/CD pipelines. Here is the CircleCI configurations:
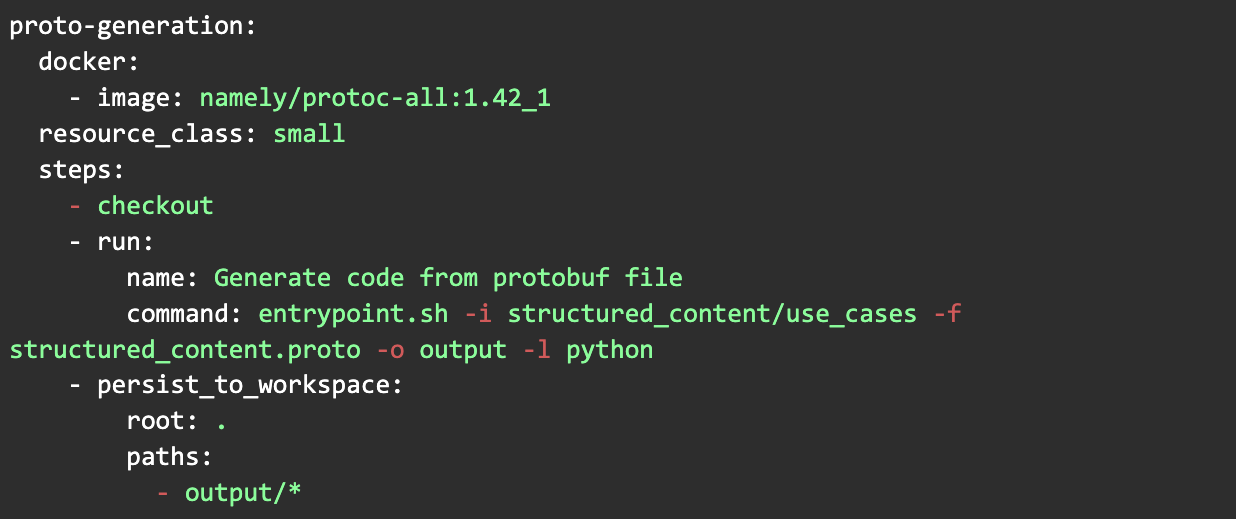
In the previous example, we are generating code for python but it can also be generated for Java, Ruby, Go, Node, C#, etc.
Once code is generated and persisted into a CircleCI workspace it’s time to publish our package.
Publishing packages
This process could be overwhelming for teams if they had to figure out how to package and publish each artifact in all supported languages in our Golden Path. For this reason we took the same approach as docker-protoc and we dockerized a tool that we developed called protop.
Protop is a simple Python project that combines typer and cookiecutter to provide us a way to package the code into a library for each language. At the moment it only supports PyPI using Twine because our main codebase of consumers are in Python, but we are planning to addGradle support soon.
The use of protop is very similar to docker-protoc. We published a dockerized version of protop to an AWS Elastic Container Registry to allow teams to use it in their CI/CD pipelines in CircleCI:
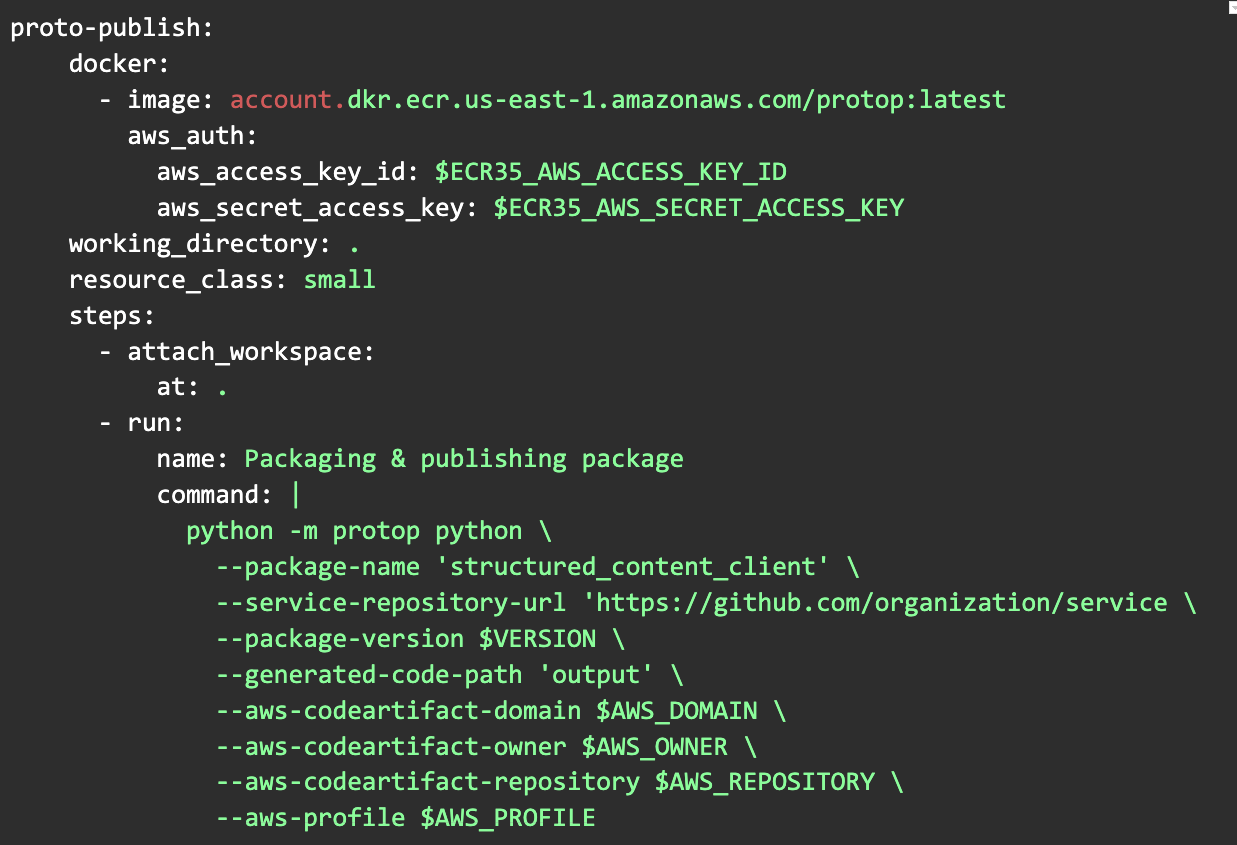
At Eventbrite we use AWS CodeArtifact in order to store other internal libraries so we decided to re-use it to store our gRPC service libraries. You can see a diagram of the overall process below.
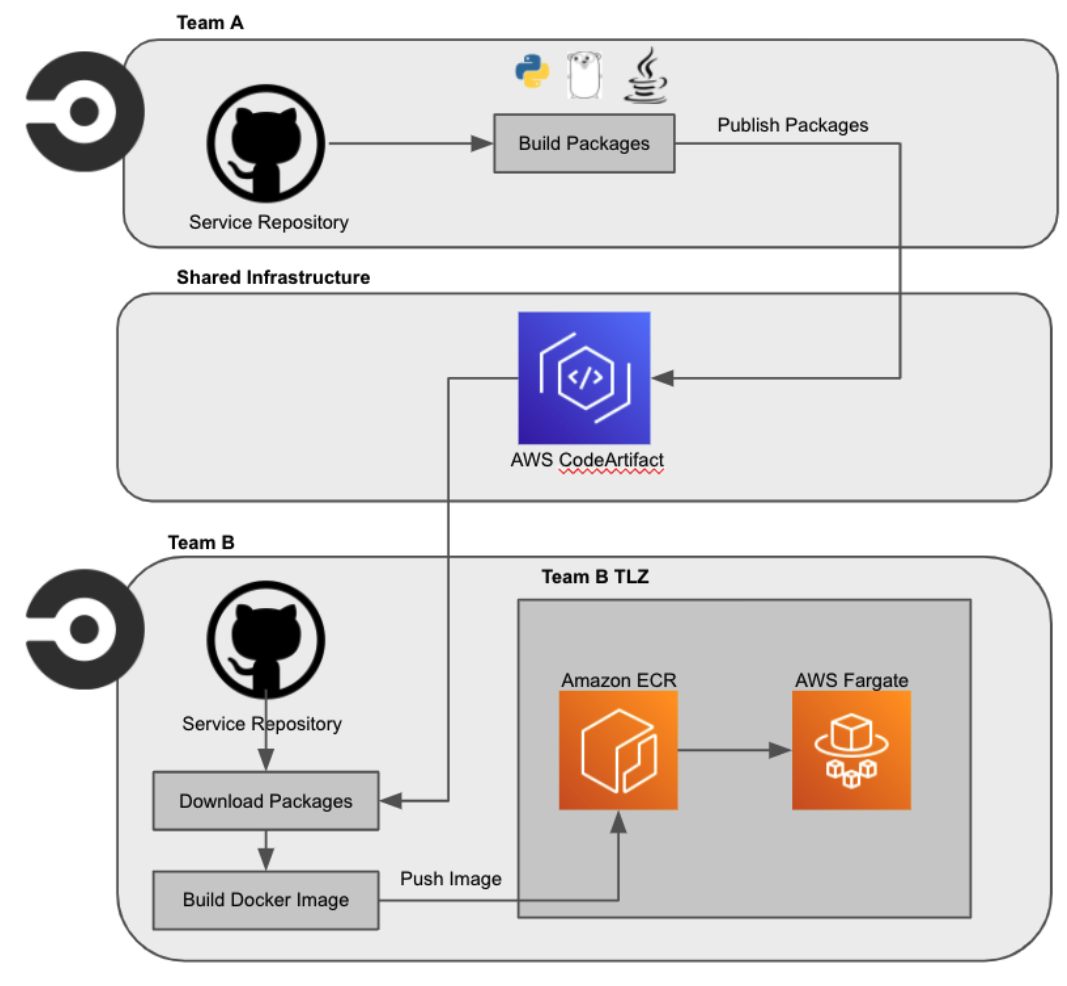
This AWS CodeArtifact repository should be shared by all teams in order to have only one common place to find those packages instead of having to ask each team what repository they have stored their packages in and having lots of keys to access them.
The teams that want to consume those packages should configure their CI/CD pipelines to pull the libraries down from AWS CodeArtifact when their services are built.
This process will help us reduce the amount of time spent in service integration without diminishing the teams’ code ownership..
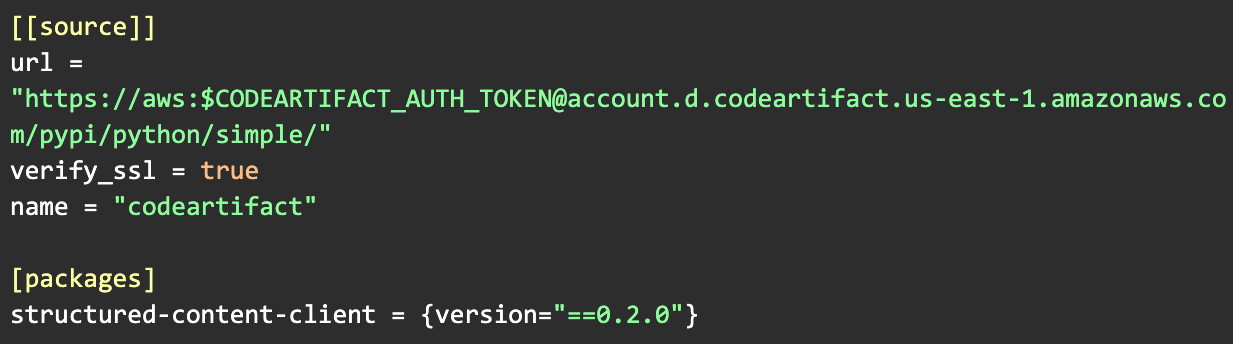
Using the packages
The last step is to use our package. With the package uploaded to AWS CodeArtifact, we need to update our Pipfile:

Conclusion
We started out by defining the challenges of managing Protobuf definitions at Eventbrite, explaining the key questions about where to store these definitions, how to manage changes and how to communicate those changes. We’ve also explained the repository and project structure.
Then, we proceed to cover protobuf validation using Buf as a linter and a breaking change detector in our CI/CD pipelines and how to version using Semantic Versioning as a way to publish and release packages’ versions.
After that, we’ve turned out to focus on how to generate, publish and consume our libraries as a kind of SDK for the service’s domain allowing other teams to consume gRPC services in a simple way..
But of course, this is the first iteration of the project and we are already planning actions to be more efficient and further reduce toil over automation. For example, we are working on generating the packages’ version automatically using something similar to Semantic Release to avoid teams having to update the package version manually and therefore avoiding error-prone interactions.
To summarize, if you want to drastically reduce the time that teams waste on service integration avoiding a lot of manual errors, consider automating as much as you can the process of generating, publishing and consuming your gRPC client libraries.






